
I’ve seen many analysis processes start the same way. Starting points are some Python scripts, a scheduled cron job, and possibly a manual run of a notebook when a report is required. At first everything worked well. The models run, the results look correct, and the system seems fairly easy to manage.
But as more models, liquidity forecasts, stress tests and risk simulations are added, the process slowly becomes a fragile chain of scripts. One failure breaks everything in the process, debugging becomes painful, and reproducing historical results becomes nearly impossible.
In the end a simple question arises: “Is it possible to rerun the model exactly as it worked last month?” And the honest answer is usually “it’s not easy.” The problem is usually not the financial models themselves. It is the lack of adequate execution infrastructure and controls around it.
In this article, we will explore how to design a Python-based model execution framework for treasury analytics workloads that improves reproducibility, scalability, and maintainability.
Why Script-Based Analytics Pipelines Break
Script-based pipelines are common in early-stage analytics systems. They are quick to deploy and require minimal infrastructure. However, treasury analysis workloads are growing rapidly and simple processes are beginning to show their limitations.
Brittle model dependencies
Treasury analyzes often involve multiple models that depend on each other. For example:
- Each stage depends on the results of the previous stage.
- Without orchestration, these dependencies become fragile chains of scripts. If one model fails, the entire process breaks.
- Troubleshooting becomes slow because there is no centralized execution tracking and logging.
Execution frameworks explicitly define dependencies and manage the order in which models are executed to solve these problems.
Reproducibility challenges
Another common problem is reproducibility. Analytics pipelines evolve frequently due to:
- The models are updated
- Parameters change
- Data sets are updated
If these changes are not systematically tracked, it is extremely difficult to reproduce historical results. For financial institutions, this is more than an inconvenience. Reproducibility is often required for internal validation, regulatory reviews and audit processes.
An execution framework helps maintain reproducibility by tracking:
- Model versions
- Old data set versions/dates
- Execution parameters
- Execution timestamps
Limited scalability
Treasury analyzes often require running models on many combinations of portfolios, scenarios, and time horizons. For example, a stress testing exercise may require running the same model under hundreds of simulated market conditions. Sequential execution of scripts becomes inefficient in these cases. An execution framework allows parallel or distributed executions, which significantly reduces execution time.
Lack of observability
Another challenge with ad-hoc pipelines is limited visibility. When failures occur, teams may not know:
- Which model failed?
- What data/lack of data caused the failure?
- How long did the model work?
- Were the results stored correctly?
Execution frameworks simplify problem diagnosis and operational reliability with systematic logging and monitoring.
Treasury Analytics Workloads in Practice
Treasury analytics platforms typically run several categories of computational workloads. Understanding these patterns helps guide architectural decisions.
Batch model execution
Many treasury models operate on scheduled intervals, such as:
- Daily liquidity forecasts
- Weekly exposure calculations
- Monthly stress testing exercises.
- Annual Backtests
These batch jobs analyze large sets of financial data for treasury and risk departments. They need reliability and repeatability because of their schedule.
Chained Model Pipes
Some models rely on upstream outlets. For example:
Market Data + Position Data → Volume Forecast Model → Portfolio Aggregation
This dependency structure naturally forms a directed acyclic graph (DAG). Execution frameworks can interpret this DAG structure and ensure that models are executed in the correct order.
Scenario and sensitivity simulations
Scenario analysis is common in treasury analysis. The equipment can simulate economic conditions such as:
- Interest rate shocks
- Currency volatility
- Liquidity stress scenarios
Each scenario requires independent model runs. Multiply this by multiple portfolios and time horizons and computing demand grows rapidly. A well-designed execution framework allows these workloads to scale efficiently.
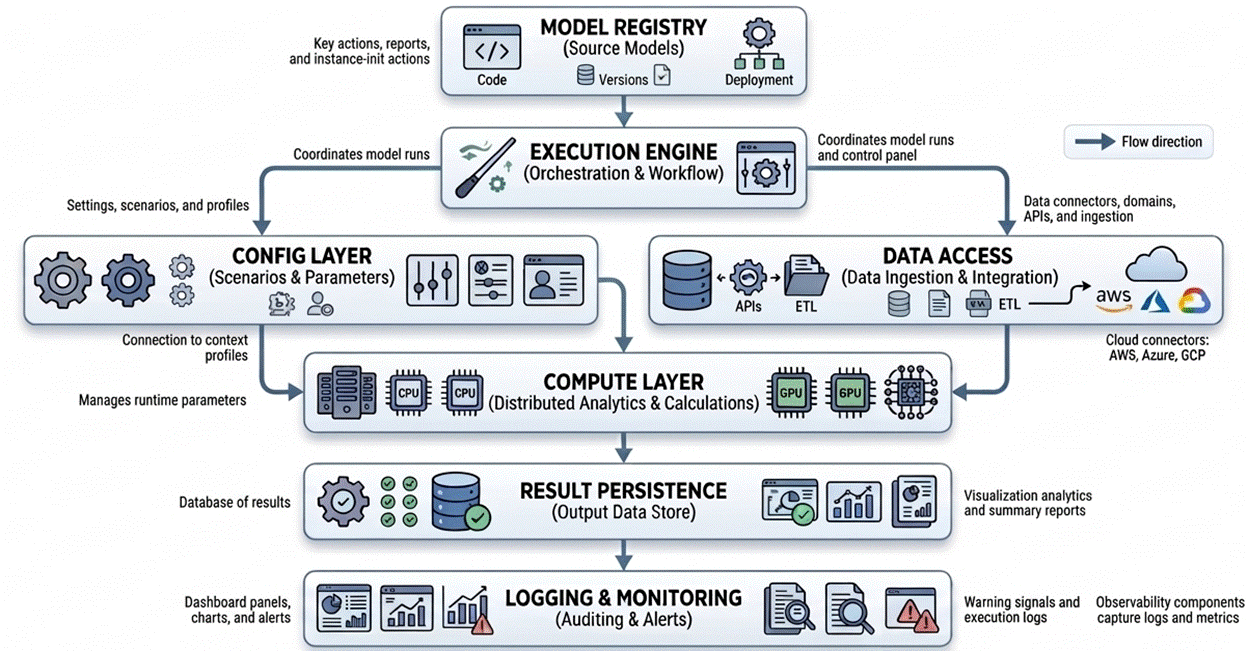
Architecture Overview
This architecture separates model logic from orchestration and infrastructure, allowing models to focus on analysis while the framework executes and monitors them.
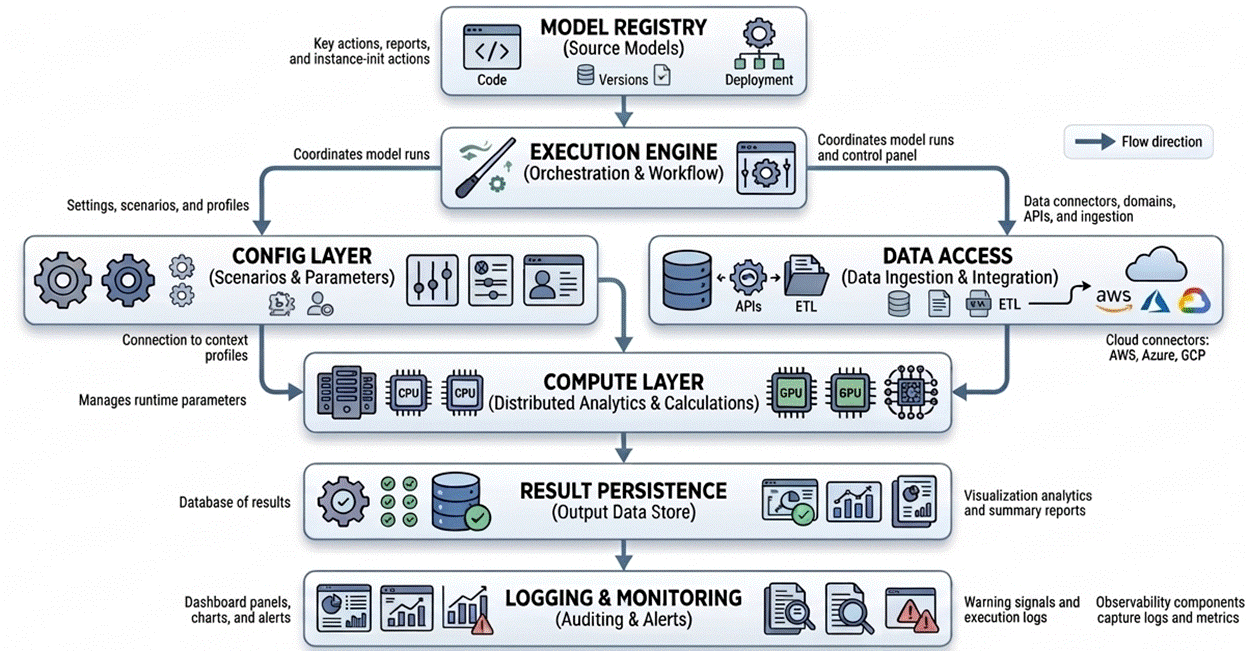
Each component has a specific purpose:
- Model Registry stores metadata about available models (example: model name, ID, version, etc.)
- Execution Engine Coordinate Model Executions
- The configuration layer manages runtime parameters (example: execution date, scenario name, etc.)
- The data access layer retrieves data sets from upstream systems (example: connection details, query definitions, etc.)
- Compute Layer runs the calculations to produce results (example: cash flow engine, etc.)
- The persistence layer stores execution results and metadata (example: model results, DQ checks, etc.)
- Observability components capture logs and operational metrics.
Step 1: Define a standard model interface
The first step in building the framework is to define a consistent interface for the models. Without a standard interface, each model requires custom execution logic. Python’s abstract base classes provide a simple way to enforce structure.
piton
from abc import ABC, abstractmethod
class BaseModel(ABC):
@abstractmethod
def ingest_data(self, data_layer):
pass
@abstractmethod
def preprocess(self, data):
pass
@abstractmethod
def compute(self, processed_data):
pass
@abstractmethod
def generate_output(self, results):
pass
@abstractmethod
def shutdown(self, logger):
pass
Each model follows the same life cycle:
- Ingest required data
- Preprocess inputs
- Run core calculation
- Generate structured results
- Close the model run (for example, print the end of model run message, close log files, flush buffered data, etc.)
Step 2: Organize models as Python packages
As the number of models grows, the organization of the code base becomes increasingly important.
Example repository structure:
treasury-framework/
models/
liquidity_model/
stress_test_model/
risk_aggregation_model/
core/
base_model.py
registry.py
data/
ingestion.py
validation.py
execution/
engine.py
config/
loader.py
Shared utilities typically include:
- Data validation routines
- Database Connectors
- Financial transformations of time series
- date utilities
- Log generation
Step 3: Implement a model registry
A model registry provides a centralized catalog of available models.
Each ticket typically includes:
- Model name
- Version
- Package dependencies and versions.
- Input data schema
- Configuration templates
Example log entry:
yaml
model_name: loan_prepayment_projection
version 1.0
package_dependencies:
- pandas 2.3.2
- numpy 2.3.3
input_schema: prepayment_schema_v1
The runtime queries the registry to load models dynamically. Registries also support version control, allowing teams to rerun historical versions of the model when necessary.
Step 4: Execute based on configuration
Parameters hard-coded within the model code quickly become difficult to manage. Instead, execution parameters must be externalized in configuration files.
Example:
execution:
portfolio_id: loan_new_volume
scenario: base
mev_vintage_date: 2026-03-31
run_date: 2026-04-01
data:
market_data_source: vendor_feed
lookback_days: 365
model_parameters:
liquidity_threshold: 0.1
Configuration-based execution provides:
- Reproducible runs
- Simpler scenario testing
- Cleaner model code
Step 5: Implement a data access layer
Models should avoid direct queries to the database. Instead, a data access layer should encapsulate upstream systems to obtain data.
piton
class DataAccessLayer:
def get_market_data(self, start_date, end_date):
pass
def get_portfolio_positions(self, portfolio_id, as_of_date):
pass
This abstraction ensures a consistent data format and allows storage systems to evolve without breaking model implementations.
Step 6: Build the Execution Engine
The execution engine organizes the life cycle of the model.
piton
class ExecutionEngine:
def int(self, registry, data_layer, utility):
self.registry = registry
self.data_layer = data_layer
self.logger = utility.logger
self.config = utility.config
def run(self, model_name):
model_cls = self.registry.get(model_name)
model = model_cls(self.config)
data = model.ingest_data(self.data_layer)
processed = model.preprocess(data)
results = model.compute(processed)
run_id = self.persist_results(model_name, results)
return run_id
In production systems, the runtime can also handle:
- job scheduling
- Dependency resolution
- Parallel execution
- Retry logic
Example: A Simple Loan Volume Projection Model
To illustrate how the models integrate with the framework, consider a simplified new loan volume projection model. The following example estimates the number of new loans that will be originated in one year. While real treasury models involve much more complex calculations, the example demonstrates how the model logic fits into the execution framework.
piton
class NewVolumeModel(BaseModel):
def ingest_data(self, data_layer):
portfolio = data_layer.get_loan_positions("treasury_loan_portfolio", "2025-12-31")
market_data = data_layer.get_market_data("2025-01-01", "2025-12-31")
return portfolio, market_data
def preprocess(self, data):
portfolio, market_data = data
return portfolio, market_data
def compute(self, processed_data):
portfolio, market_data = processed_data
target_ratio = 0.54
new_volume = portfolio("previous_month_balance").sum() * target_ratio
return{
"new_volume": new_volume
}
def generate_output(self, results):
return Results
A model run might look like this:
piton
engine.run(
model_name = "loan_volume_projection",
config = "configs/volume_scenario.yaml"
)
The framework registers a run ID, ensuring that results remain traceable and reproducible.
Running the scale model
As workloads grow, the framework should support scalable execution strategies.
Parallel portfolio execution
Independent model runs can be run simultaneously across all portfolios:
Portfolio A → Model Execution
Portfolio B → Model Execution
Portfolio C → Model Execution
This significantly reduces the total execution time.
Efficient data processing
Large sets of financial data can overload memory. Libraries like Polar Provides faster data frame operations and improved memory efficiency compared to traditional Pandas workflows.
Observability and tracking
Reliable analytics platforms require strong observability.
Structured registration
Logs should capture:
- Model name
- run ID
- vintage dates
- Parameters used
- Execution status
Execution metrics
Metrics can track:
- Run Duration
- Memory usage
- Data set sizes
Model governance and reproducibility
Financial analytics platforms must support strong governance practices. Execution frameworks should keep track of:
- Model versions
- Configuration parameters
- Data set versions
- Execution timestamps
This metadata creates a complete audit trail, allowing teams to replay historical model runs when necessary.
Conclusion
Analytics teams can develop a scalable and reliable analytics infrastructure by structuring model execution around logs, configuration layers, and orchestration engines, replacing fragile script-based workflows. Treasury analyzes are becoming more complex. Modern financial platforms require reliability, scalability and governance, which simple scripts cannot provide.
A practical approach is to start small. Start by registering some models and implementing a simple execution engine. Gradually introduce configuration-based execution. Over time, this system can enable large-scale simulations, forecasting models, and advanced financial analysis in a treasury analytics platform.



