
I recently started integrating on-premise LLMs with my arsenal of free and open source tools, and they have been a game-changer for my productivity needs. Whether generating precision OCR Scans or help me rewrite long chunks of code When properly indented, self-hosted models are surprisingly capable of automating everyday tasks. What’s more, the FOSS ecosystem has tons of obscure AI tools that are productivity powerhouses, as long as you use them for the right tasks.
Grab the Ebook2Audiobook repository from the genius developer DrewThomassonFor example. Able to pair my GPU with text-to-speech engines, this elegant app can turn any old document, whether a simple note or an entire e-book, into a decent podcast. While it’s no replacement for conventional e-books, it’s easily one of the best research companions I’ve found in a long time.
Ebook2Audiobook runs the entire text-to-speech process locally
And its web user interface makes the process quite simple.
Compared to cloud models that require large subscriptions to generate podcasts and audiobooks without running out of API credits, Ebook2Audiobook is a completely local tool that doesn’t drain my wallet every month. Plus, since nothing leaves my network, I don’t have to worry about some random company training new underground people with my private data.
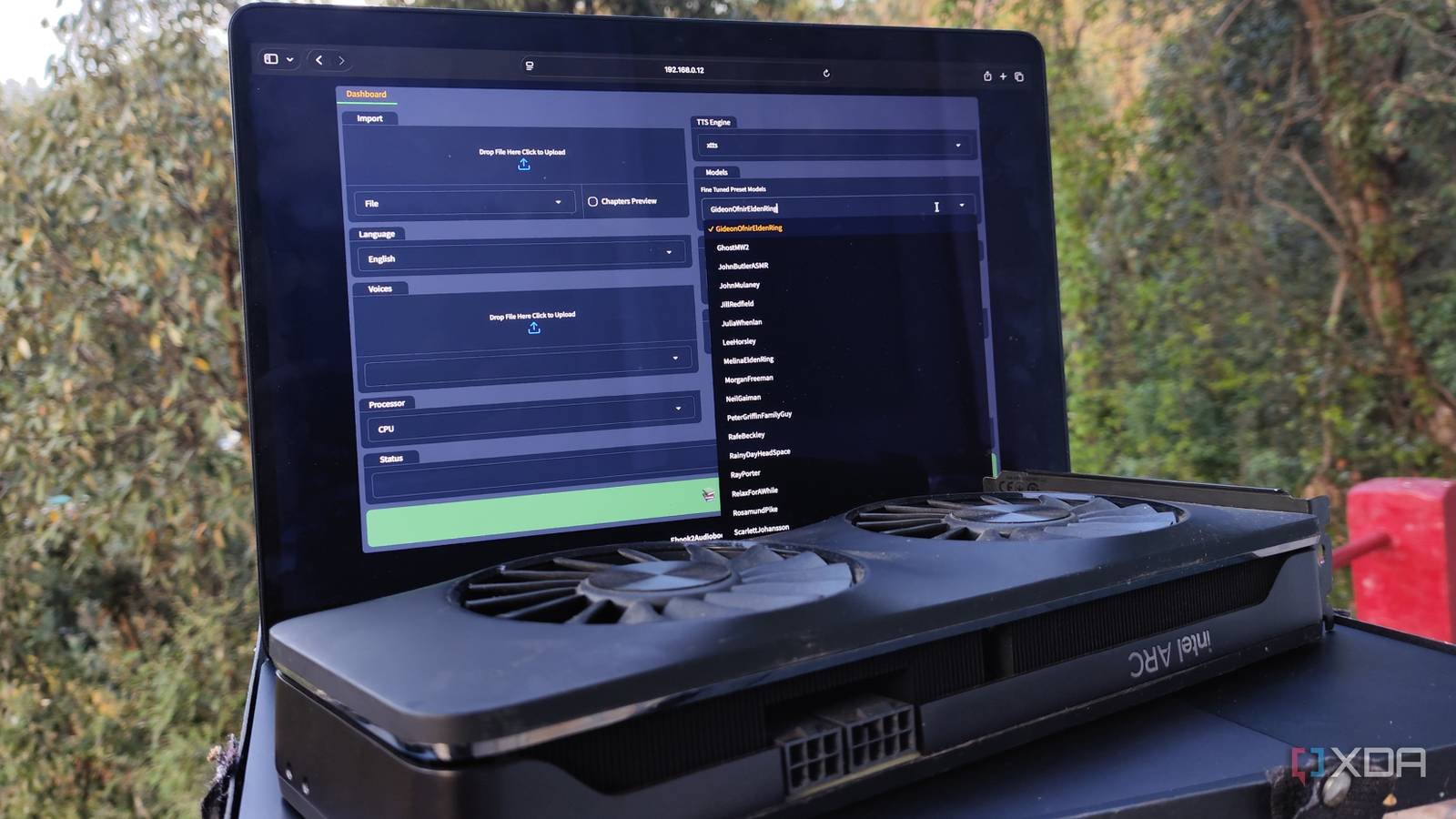
In terms of accessibility, Ebook2Audiobook is quite easy to get up and running. Implementing it on my Windows machine involved creating a directory for your files and running the docker run -v “./ebooks:/app/ebooks” -v “./audiobooks:/app/audiobooks” -v “./models:/app/models” -v “./voices:/app/voices” -v “./tmp:/app/tmp” –gpus all –rm -it -p 7860:7860 athomasson2/ebook2audiobook:cu130 domain. For reference, I deployed the app on a system equipped with an RTX 3080 Ti and the CUDA version of its Docker image recognized the card immediately.
Ebook2Audiobook also has a dedicated web UI, so I don’t have to run long terminal commands just to change the text-to-speech engine or present model. In fact, the XTTS engine includes a ton of audio presets, including video game characters, but it also allows me to add custom HuggingFace models. Just for a laugh, I selected Gideon Ofnir’s profile from Elden Ring, uploaded the .wav file containing his voice sample from Drew Thomasson HuggingFace Library and threw in a previous article of mine as input text. Within seconds, my GPU came to life and Ebook2Audiobook began its magic. For an article with about 900 words, it took Ebook2Audiobook about 2-3 minutes to generate a 6-minute audio clip from “The All-Knowing” rambling about how to turn the Raspberry Pi into a pocket-sized Linux server.
Jokes aside, the audio wasn’t terrible by any means. While there were occasional errors with certain technical words (specifically terminal commands and technical abbreviations), it was surprisingly decent for something that runs entirely on my local GPU. I ended up downloading different models from HuggingFace and after playing with the settings, the generated MP3 was good enough to cover my academic material.
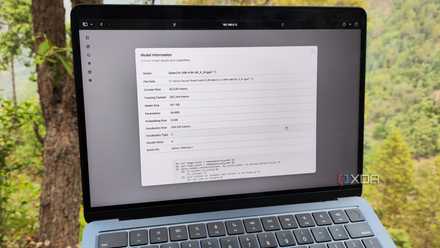
It also has enough customization options.

While we’re on the topic of settings, I love how Ebook2Audiobook’s web UI includes a ton of options for tweaking TTS tasks. I’ll stick with XTTS and Bark for converting my notes to audio files, but Tortoise is pretty good, while Fairseq is decent for low-end systems (although audio quality takes a noticeable hit). Ebook2Audiobook also includes a detailed settings tab for most text-to-speech engines, and the one from XTTS features options for everything from temperature to top-k and top-p. sampling values. I’ve played around with these settings quite a bit and they can turn boring old documents into whimsical narratives. Or end up turning everything into strange valley creations if you go crazy with their values. Yes, I speak from experience.
Ebook2Audiobook is great for turning academic notes into audio-rich narrations
I’ve even started using it for research tasks.

To be brutally honest, I wouldn’t go so far as to say that Ebook2Audiobook can replace the effort put into conventional audiobooks. Instead, I love using it to add narration to my notes and all the research material I collect before working on a paper. Instead of reviewing pages of text or asking LLMs to summarize them, thus losing a lot of context, I simply send the entire document to Ebook2Audiobook, tweak the speed settings a bit, and listen to the impromptu podcast while I work on my tasks.
Specific terms and CLI commands aside, Ebook2Audiobook is pretty good at adding narration to my carefully compiled notes. With the right model and a handful of TTS engine modifications, it’s good enough to keep my mind busy with virtualization research material while I work on fake menial tasks.



