

Since jumping headfirst into the local LLM rabbit hole, I’ve taken to revitalizing old PCs by turning them into reliable AI workstations. With the right settings, I’ve even managed to run powerful LLMs that can rival their cloud-based counterparts on something as old-fashioned as a 10 year platform. That said, most of my most intense LLM experiments involve full x86 gaming systems with dedicated graphics cards and excess RAM.
That said, a Raspberry Pi 5 can handle up to 4B models without buckling under the extra load, making it a surprisingly decent option for hosting. embed models and simple chatbots. But since I wanted to run models that wouldn’t otherwise fit in this SBC, I thought I’d try bundling up some spare boards. And well, it’s probably one of the most cursed projects I’ve ever worked on (but it still has some use).
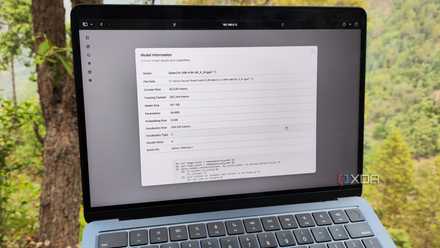
Building a llama.cpp cluster was not that difficult
However, I had to compile the inference engine on both systems.
Starting with the SBCs I wanted to use as guinea pigs Participants in this project had initially planned to create a group of three devices. However, I quickly realized that most of my ARM boards were already running some experiment or another, leaving a Raspberry Pi 5, High free computerand Le Frite as the only viable options. Unfortunately, Le Frite is extremely weak for this project, and its USB 2.0 and 100M connector would end up hindering an already weak setup. So, I opted for a 2-node cluster involving a Raspberry Pi 5 (8GB) and a Libre Computer Alta (4GB), with an RPC backend in llama.cpp that splits the inference tasks between the two systems.
Fortunately, the setup process was much easier than I had anticipated, although I did have to compile llama.cpp from scratch. Once I built both systems with a CLI distro (an older version of Ubuntu on Alta and Raspberry Pi OS Lite on you-know-what) and configured openssh serverI logged into them via PuTTY and installed the prerequisite packages by running sudo apt install -y git build-essential cmake pkg-config. Then, I cloned the llama.cpp repository with git clone https://github.com/ggml-org/llama.cpp.git and changed to your newly created directory via the cd llama.cpp domain. Finally, I created another folder called build-rpc through mkdir -p rpc-compile before switching to it and running the following commands to compile llama.cpp with RPC capabilities:
cmake .. -DGGML_RPC=ON -DCMAKE_BUILD_TYPE=Release
cmake --build . --config Release -j$(nproc)
Since I wanted Alta SBC to act as a secondary server, I ran ./bin/rpc-server -H 0.0.0.0 -p 50052 on it and let the RPC server stay up for a while. After using the SCP command to move some LLM from my main PC to the Raspberry Pi node, I ran the ./bin/llama-server -m /home/ayush/models/Qwen3.5-2B-Q4_K_M.gguf –rpc 192.168.0.150:50053 –host 0.0.0.0 –port 8080 command and waited for it to finish loading the model.
It turns out that the cluster’s performance was worse than that of a standalone SBC.
I blame slow network provisions for this bottleneck.

Since I was using the fairly lightweight Gemma 3 4B, I expected my cluster to perform a little better than just my Raspberry Pi. However, running a couple of prompts through the calling server’s web UI proved otherwise. And I’m not talking about complex prompts or inference tasks involving MCP servers either. For something as simple as “Tell me something interesting”, the cluster would struggle to reach 2.20 tokens/second. So, I rebooted my Raspberry Pi and ran the llama-server command once again. Except this time I got rid of the –rpc flag. Sure enough, the inference engine managed to reach 4.37 t/s, which is almost twice as fast as the pooled configuration!
In theory, the cluster should achieve higher token generation rates or, at the very least, provide speeds comparable to a Raspberry Pi-only setup. But it makes a lot of sense if we factor network and storage bottlenecks into the equation. You see, both SBCs feature a 1GbE connection, which is a bit slow for high-speed AI inference tasks. Worse yet, I ran out of SSDs in my home lab, so I had to make do with simple microSD cards, which definitely contribute to the speed factor (or lack thereof). Add in the fact that LLM operations are very latency sensitive and it’s clear why my cluster is performing horribly. I was about to label this project a failure and end it here, but I wanted to try one last experiment before disbanding the group…
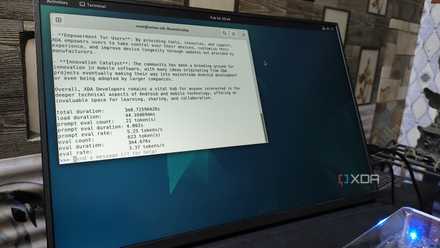
But the cluster can run LLMs that would otherwise be too heavy for my RPi.
Just don’t look at token generation speeds.

While its lackluster performance was a complete stir, my main goal behind this extravagant project was to run large models that a Raspberry Pi with only 8GB of RAM couldn’t accommodate. So, I started llama-server once again without the RPC flag and started increasing the model parameter size. Qwen 3.5 (9B) is where the server calls failed, as the SBC couldn’t accommodate the large model.

But when I ran it with the RPC flag pointing to High, llama-server was able to load the LLM with relative ease. Just to satisfy my curiosity, I opened the web UI and started applying for the LLM. Well, it definitely worked, although it was only able to generate 1.27 tokens per second. That’s not even close to a feasible number for my productivity tasks and coding workloads. But it’s still useful for automated tasks like generating labels for bookmarks or performing OCR scans on documents, especially considering I can leave my SBCs running all day without worrying about their power consumption.
And to be brutally honest, I thought I would end up measuring seconds per token instead of tokens per second. So a token generation rate of 1.27 t/s is somewhat surprising, especially since it’s a model that my SBC couldn’t even load in the first place. While I probably wouldn’t use this cluster for SBC inference tasks, RPC definitely seems useful. In fact, I might try using it for my current LXC-based LLM hosting workstations, which feature full 10G NICs.



